
What are Vectors?
Vectors convert your text data into numerical representations (embeddings) that capture semantic meaning. This enables:- Semantic search - Find relevant content based on meaning, not just keywords
- RAG applications - Enhance AI agents with contextual information from your data
- Similarity matching - Identify related documents or records
Creating a Vector Index
- Navigate to your Project page
- Click the Add button (+ icon)
- Select Vector from the dropdown
Step 1: Choose Data Source
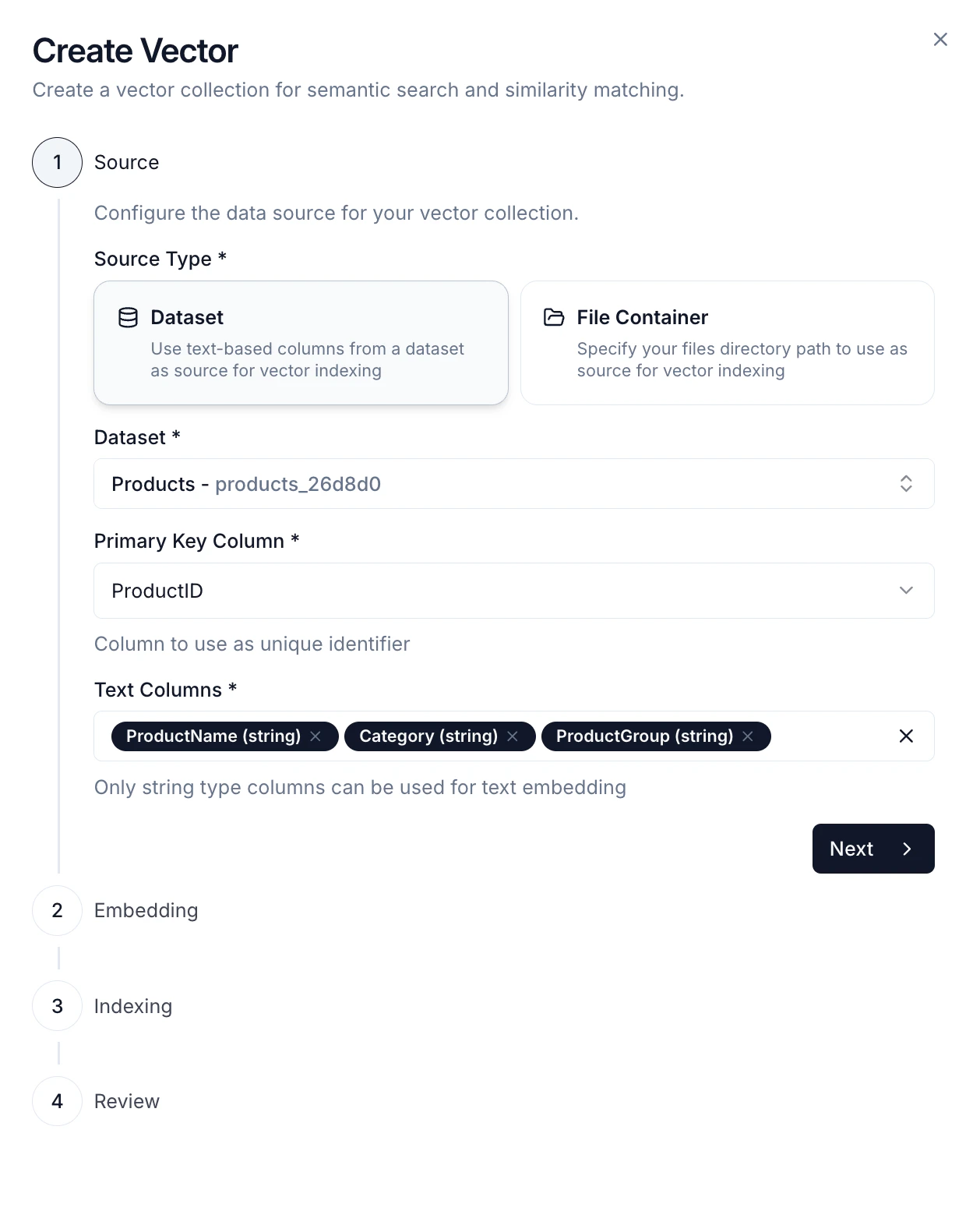
- Dataset - Index data from a dataset (CSV format)
- Select the dataset you want to vectorize
- Choose a primary key column to uniquely identify records
- Select one or more text columns to embed
- File Container - Index files from a file container path
- Supported formats: PDF, CSV, DOCX, XLSX, Markdown, TXT
- Files will be automatically processed and chunked
Step 2: Embedding Configuration
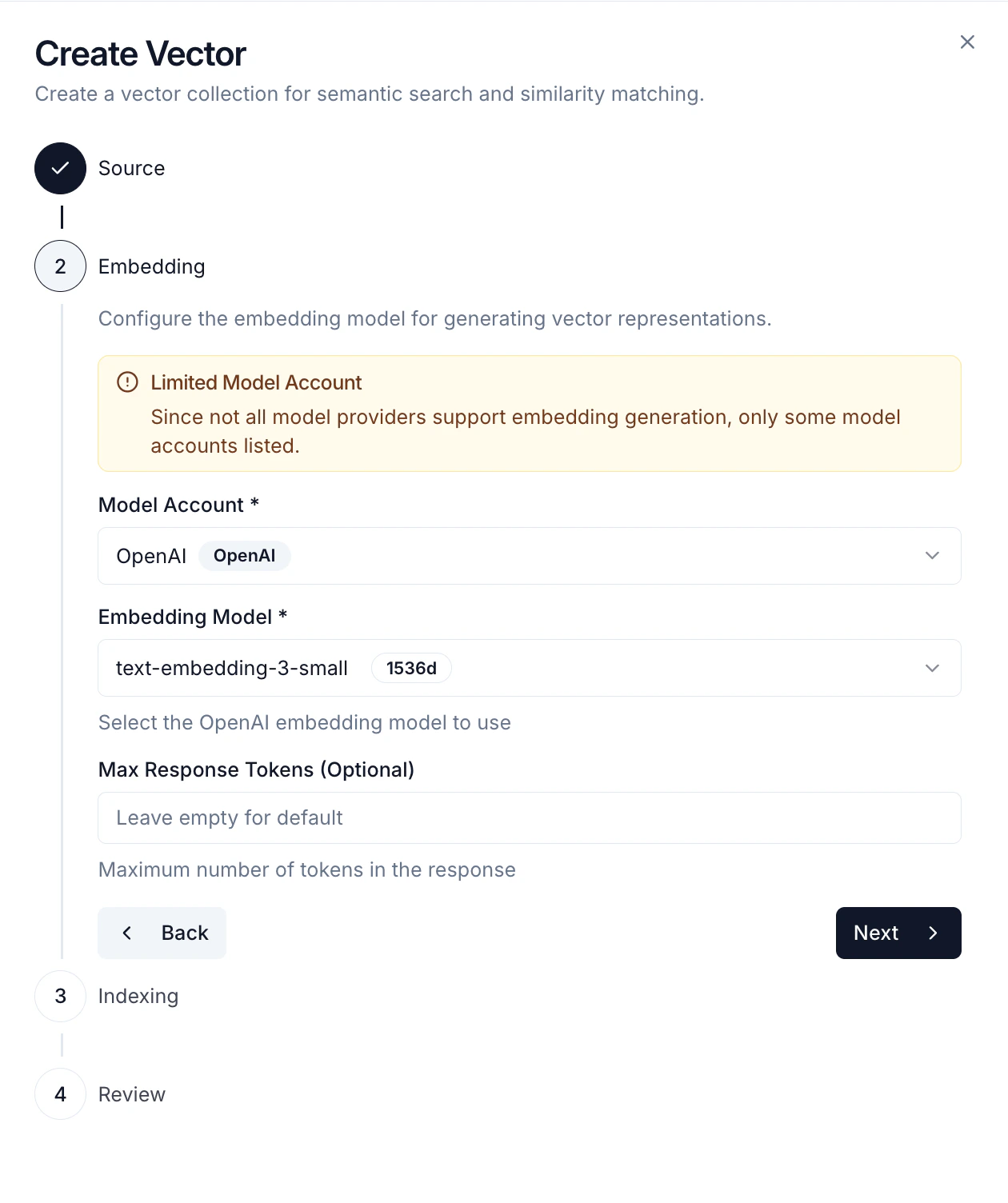
- Model Account - Select a configured Model Account with embedding support
- Embedding Model - Choose the embedding model (e.g.,
text-embedding-3-small,text-embedding-ada-002) - Vector Dimension - Embedding dimension (typically 1536 for OpenAI models)
Step 3: Chunking Strategy
Configure how your text is split into chunks before embedding:- Text Splitting - Split by character count
- Chunk Size - Number of characters per chunk
- Chunk Overlap - Characters shared between chunks (helps maintain context)
- Length Splitting - Split by token count using a specific encoding
- Encoding Name - Tokenizer to use (e.g.,
cl100k_basefor GPT models) - Chunk Size - Number of tokens per chunk
- Chunk Overlap - Tokens shared between chunks
- Encoding Name - Tokenizer to use (e.g.,
- Document Splitting - Split based on document structure
- Document Type - Choose format: Markdown, JSON, Code, or HTML
- Preserves logical document boundaries
Smaller chunks provide more precise search results but may lose broader context. Larger chunks retain more context but may be less specific. A typical chunk size is 500-1000 characters with 10-20% overlap.
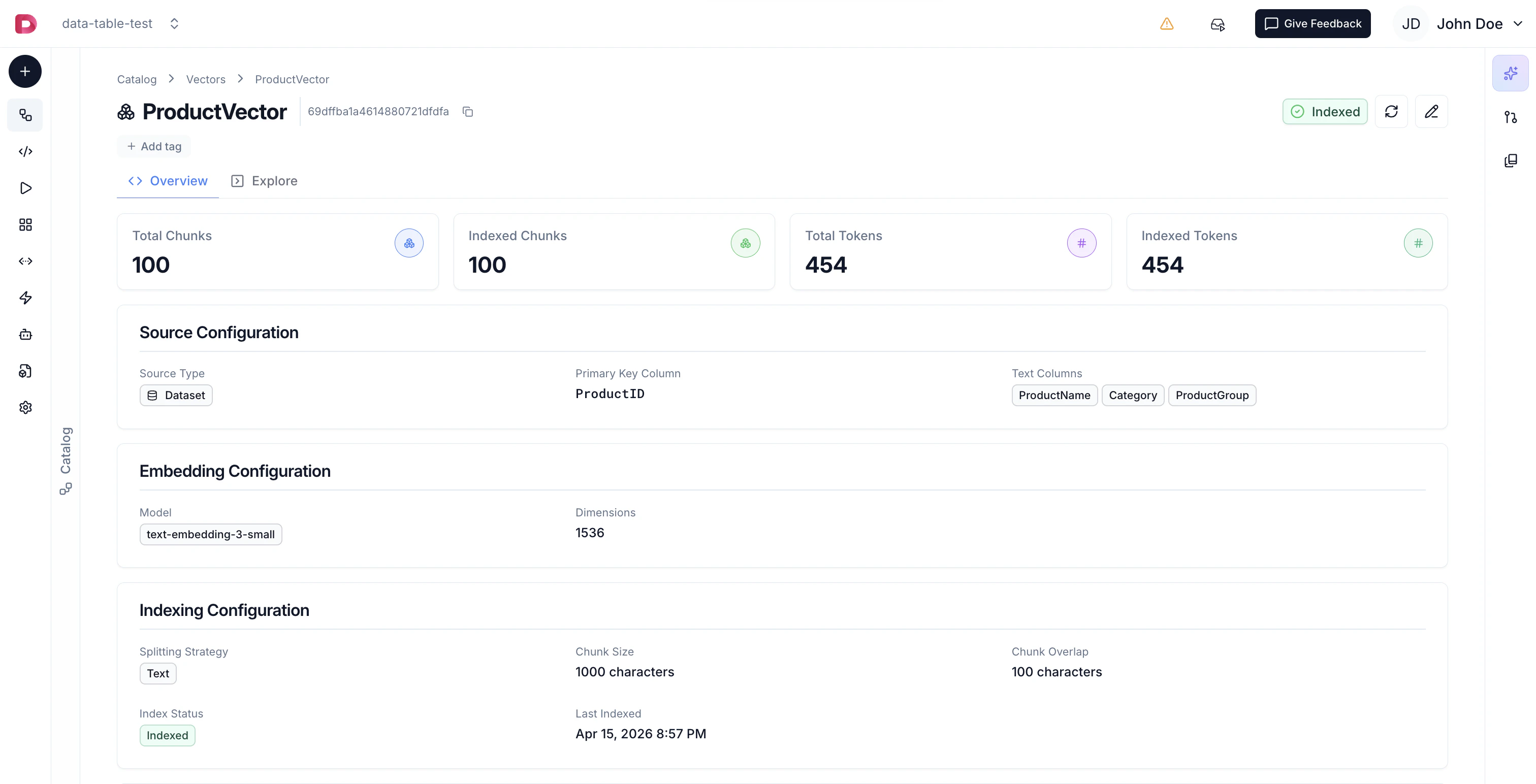
Indexing Process
Once created, your vector index goes through several states:- Not Indexed - Initial state after creation
- Scheduled - Queued for indexing
- Indexing - Currently processing and embedding your data
- Indexed - Successfully completed, ready to use
- Failed - Error occurred during indexing (check error details)
- Total chunks created
- Total chunks indexed
- Total tokens processed
Using Vectors
Once indexed, your vectors can be used for:Semantic Search
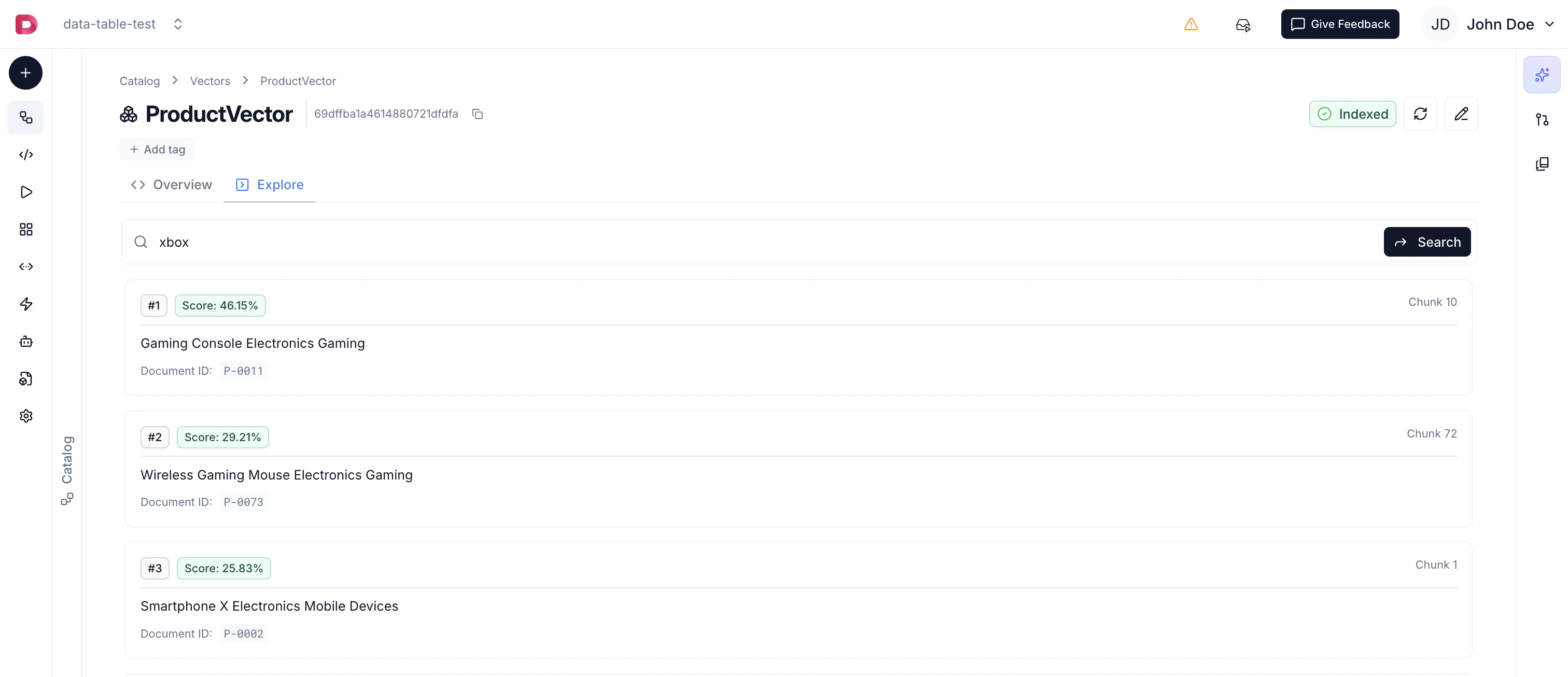
- Enter search queries in natural language
- View semantically similar results ranked by relevance
- See matching chunks with their context and metadata
- Test and refine your vector search results
Agent RAG
Attach vectors as data sources for your Agents, enabling them to retrieve relevant context from your data to provide more accurate and informed responses. Agents can automatically perform semantic search when answering questions.Similarity Endpoints
Create API endpoints that return similar records based on vector similarity, enabling semantic search in your applications. Perfect for building search features or recommendation systems.Best Practices
- Choose the Right Source - Use datasets for structured data and file containers for documents
- Optimize Chunk Size - Balance between context (larger chunks) and precision (smaller chunks)
- Add Overlap - Include 10-20% overlap to maintain context across chunk boundaries
- Select Appropriate Models - Smaller embedding models are faster and cheaper, larger models may provide better quality
- Use Cosine Similarity - Works well for most text similarity use cases
- Monitor Indexing - Check indexing status and statistics to ensure successful processing
Next Steps
- Configure Model Accounts for embedding models
- Create Agents to leverage your vectors
- File Containers for document management