Core Entities
Source
Think of Sources as secure gateways to your data. They act as bridges between your external data systems (databases, cloud storage, streaming platforms) and Datazone. Sources handle the crucial task of credential management and access control, typically managed by organization administrators. They ensure your data connections are both secure and efficient.Project
Projects are your data initiatives home base. They provide a structured workspace where you can organize related data work - from ingestion to analysis. Each project is a self-contained environment housing Extracts, Pipelines, Notebooks, Datasets, Schedules, Intelligent Apps, and Agents. With flexible permission settings, you can control who accesses what, making it perfect for both team collaboration and data governance.Extract
Extracts are your data ingestion powerhouses. Connected to Sources and living within Projects, they define how data should be pulled from external systems. When executed, Extracts create standardized Datasets in your data Lakehouse. Think of them as smart data movers that handle the heavy lifting of data ingestion while ensuring data quality and consistency.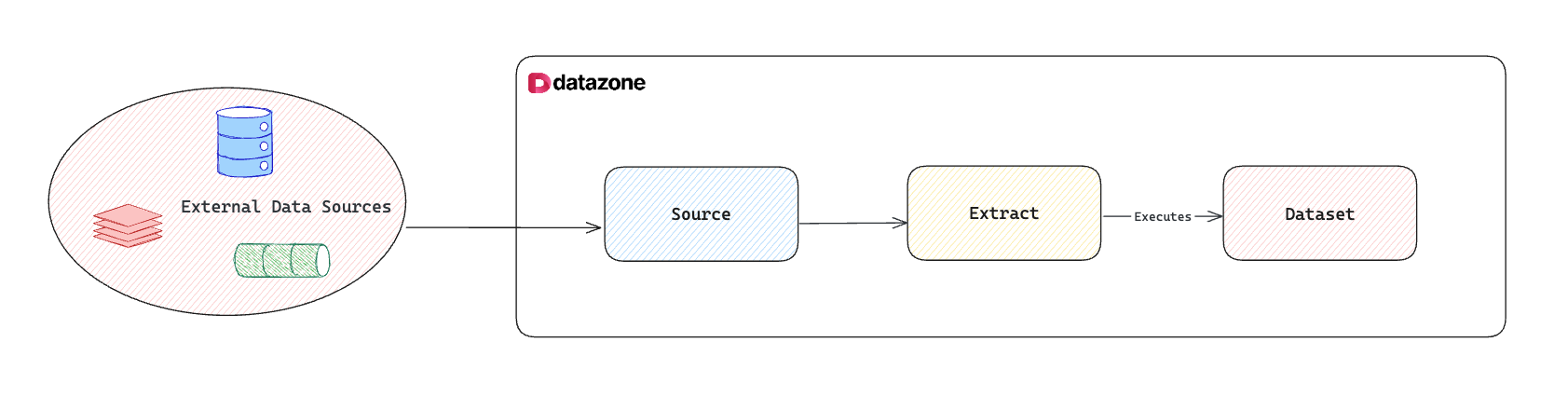
Pipeline
Pipelines are where data engineering magic happens. Built as Directed Acyclic Graphs (DAGs), they represent your data transformation workflows. Pipelines are defined in code, making them version-controlled, reusable, and maintainable. They can clean, filter, join, and reshape your data, turning raw information into valuable insights.
Schedule
Schedules bring automation to your data workflows. Using cron expressions, they orchestrate when your Extracts and Pipelines should run. They’re the timekeepers of your data platform, ensuring your data processes run like clockwork, whether it’s hourly updates or monthly aggregations.Notebook
Notebooks are your interactive playground for data exploration and analysis. Similar to Jupyter notebooks but integrated into Datazone, they provide a user-friendly interface where you can write code, visualize data, and debug your transformations. They’re perfect for both quick data investigations and detailed analysis.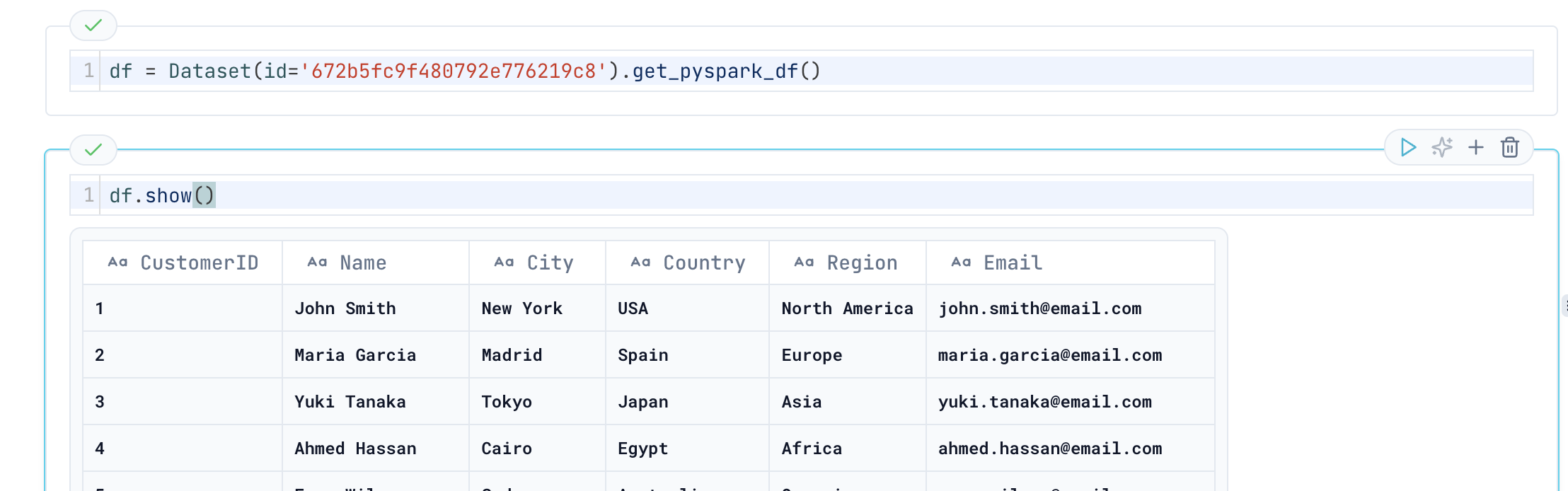
Intelligent App
Intelligent Apps transform your data into interactive dashboards and applications without requiring frontend development. Using declarative YAML configuration, you can create multi-tab dashboards with charts, filters, and dynamic visualizations that query your datasets directly. They’re perfect for building executive dashboards, operational monitoring tools, or self-service analytics interfaces that stakeholders can interact with through filters and drill-down capabilities.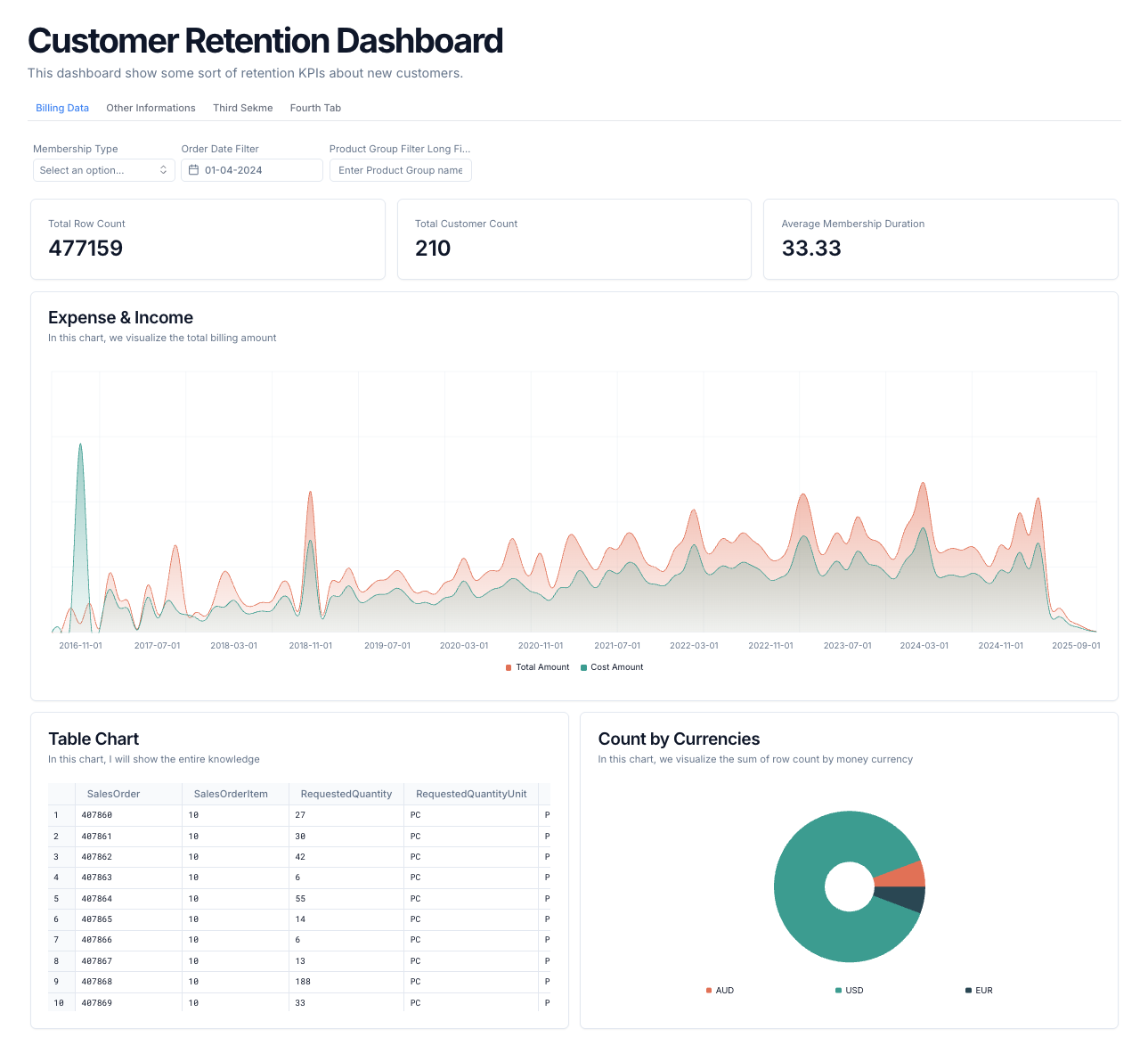
Agent
Agents are AI-powered assistants that automate data processing, analysis, and insights generation. Configured with custom instructions, they can monitor data pipelines, generate reports, trigger actions based on data conditions, and provide intelligent recommendations. Agents integrate with your data workflows to enable proactive data management, anomaly detection, and automated decision-making processes.
Endpoints
Endpoints enable you to create secure, controlled API interfaces for your datasets. They transform your processed data into RESTful APIs that can be consumed by external applications, services, or third-party integrations. With built-in authentication and authorization controls, Endpoints ensure your data is shared securely while maintaining governance standards. They’re perfect for exposing analytical results, feeding data to downstream systems, or creating data products that other teams can reliably consume.How It All Fits Together
Your data journey in Datazone typically flows like this:- Connect to external systems through Sources
- Organize your work in Projects
- Ingest data using Extracts
- Transform data with Pipelines
- Automate workflows using Schedules
- Analyze results in Notebooks
- Share insights through Intelligent Apps
- Deploy intelligent automation with Agents
- Expose data via secure Endpoints
Each entity in Datazone is designed to solve specific data engineering
challenges while working harmoniously with others. This modular yet integrated
approach makes Datazone powerful enough for complex data operations and
AI-driven automation yet simple enough for quick data tasks.