Overview
The Toolkit provides utilities to help you work with data in Datazone notebooks. Currently, it includes the Dataset class for accessing datasets.
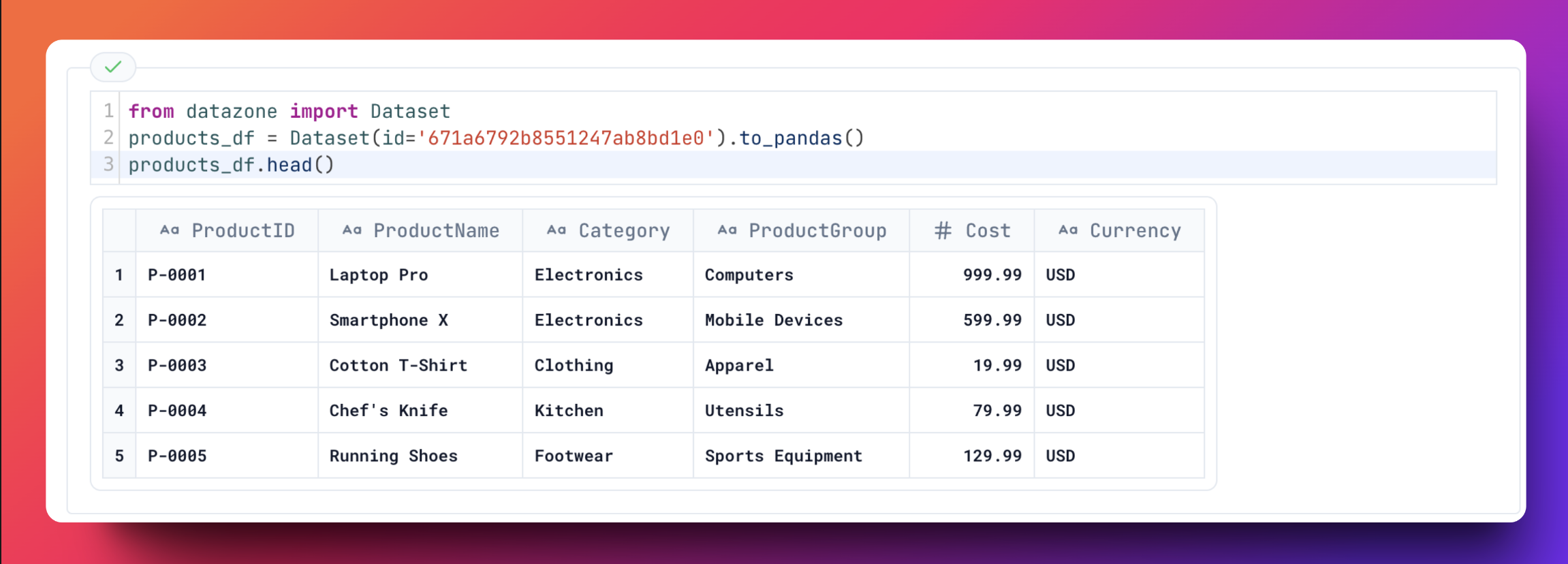
Dataset
The Dataset class allows you to easily load datasets into your notebooks as Pandas or PySpark DataFrames.
You can also load a dataset by providing a specific branch name:
Thanks to the Dataset class, you can now easily load datasets into your notebooks as Pandas or PySpark DataFrames.
get_pyspark_df() is only available in the PySpark kernel.
Variable
You can access the Variables from the kernel environment using the Variable class.
Example
Also you can check the Variables